Over the last few months I have been exploring RAG, GraphRAG, inserting documents into chat and a variety of prompting methods. How much does the contents of the context window affect the quality of what is produced? I decided to do some experiments.
I want to see if the information I provide along with a prompt matters. This is clearly a vast problem space so I decided to constrain this to the following:
- All of the questions would be business strategy questions of the kind consultants might answer and my MBA students would recognise. These questions do not necessarily have a single correct answer.
- All of the cases were fictitious but realistic and similar to real cases. It is highly likely that LLMs have been trained on similar cases and could therefore used learned patterns in answering the questions even given just a short prompt. This matches the current expected use by many business leaders of LLMs but the results of these experiments need to be read in this light.
- I needed to make sure that answers from one experiment could not affect the answers of another and so I used Claude’s API for each run. I set the temperature of each run to 0.0 to reduce creativity in the answers.
- Every agent was asked to produce 500 word answers. Perhaps longer or shorter answers would have changed the quality of the outputs.
- I wanted to compare a simple prompt with a better prompt plus test the presence or absence of “company information” that would potentially colour the answers. I created relevant material and highly irrelevant material so that assisting information and distracting information could be compared.
- I used n8n to set up my testing environment: to maintain a consistent flow holding as many variables constant as possible: same system and user prompts etc.
- I decided for this set of experiments to use other AI agents (ChatGPT and Gemini) to evaluate the output. The results could of course be invalidated by automating the judging of the answers, but as these are subjective anyway I decided that automating took me out of the evaluation process.
I ran each experiment with 6 variations:
- Minimal prompt
- Good prompt
- Minimal prompt (same as 1.) with relevant content
- Good prompt (same as 2.) with relevant content
- Minimal prompt with distracting (irrelevant) content
- Good prompt with distracting (irrelevant) content
Here is the n8n flow that I used:
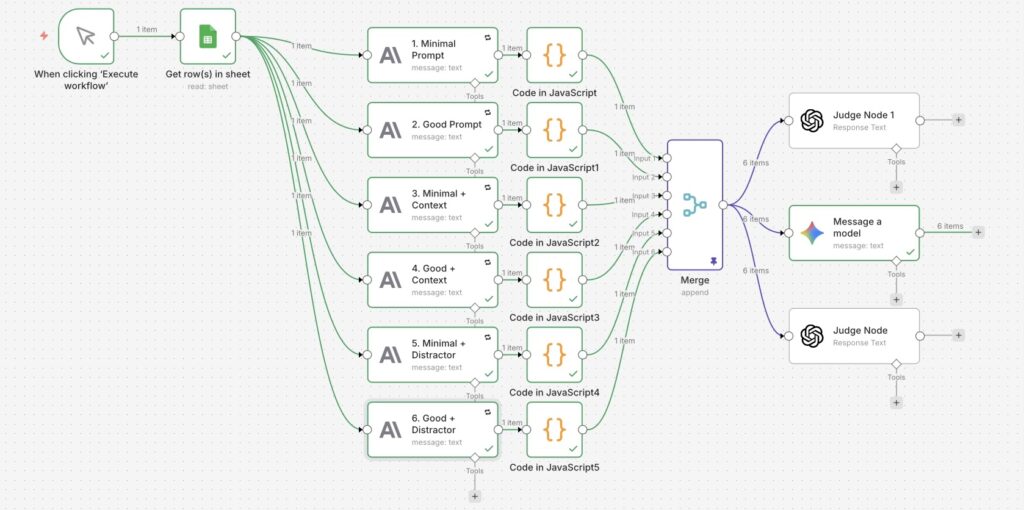
I ran 5 separate cases using the same workflow:
- a company wanting strategic options to defend its market share
- a company looking for root causes of poor repeat buying
- a company looking to prioritise a given set of strategic options
- a company looking to switch investments between product lines
- a company looking for new product ideas for a specific target audience
Here are the set of tests I ran together with results.
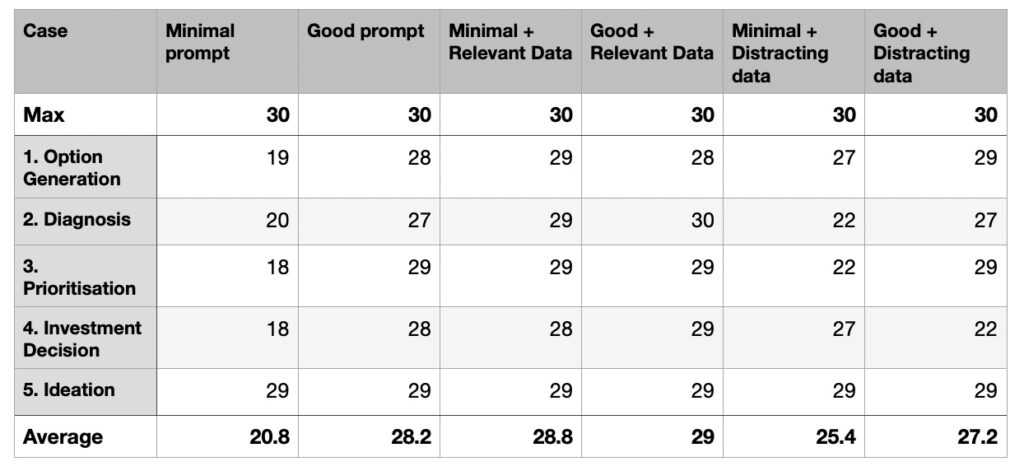
The results of these experiments are quite surprising and will need lots of future thought and further testing but can be summarised as follows:
- Good prompts appear to do a lot of work (in this domain where there are probably lots of training examples).
- A poor prompt can be rescued with relevant data. Of course a good prompt is just relevant data attached to the goal of the prompt.
- Distracting data (eg the wrong data pulled from RAG) can weaken even a good prompt.
- Adding additional data to a good prompt only marginally improves the outputs.
- Some tasks (eg the last ideation task) are well answered by even a relatively poor prompt. This is likely to be because the models are so well trained in some domains. This observation feels like it captures the surprising quality we see from current LLMs but should be a warning to keep checking the answers.
Let me know if you have questions or if you want more information on these experiments.



0 Comments